Unnest_Tokens Package In R | Could not find function unnest_tokens. Required packages & supporting functions tidytext package for reading the file containing the dataset unnest_tokens function. I want to do a bigram analysis using the function unnest_tokens from tidytext package. Since you're just looking at bigrams (two consecutive words), pass n = 2. We then need to load the package along with the tidyverse to pull out the hashtags from the text of each tweet we first need to convert the text into a one word per row format using the unnest_tokens() function from. Could not find function unnest_tokens. Usage 1.1 the unnest_tokens() function | notes for text mining 1.1 the unnest_tokens() function; Error in unnest_tokens_.default(., word, reviewtext) : After using unnest_tokens, we've split each row so that there is one token (word) in each row of the new data frame; R/unnest_tokens.r defines the following functions: This package implements tidy data principles to make many text mining tasks easier, more effective, and consistent with tools already in wide use. Tidytext will allow us to perform efficient text analysis on our data. 9.2 tokenise the text using unnest_tokens(). In this case, you'll call unnest_tokens() passing the token argument ngrams. In this example each id represented a tweet, so when i had unnested it, the words were each given a sentiment score. Learn how to use the tidytext package in r to analyze twitter data. Most analysis involves tokenising the text. The default tokenizing is for words, but other. Unnest_tokens(tbl, output, input, token = words, format = c(text, man, latex, html, xml), to_lower = true, drop = true. Df %>% unnest_tokens(word, text) %>%. The tidyr package provides the ability to separate the bigrams into individual words using the separate() function. The janeaustenr package will provide us with the textual data in the form of books authored by the novelist jane austen. The default tokenization in this function uses the tokenizers package to separate each line of text in the original data frame into tokens. Most analysis involves tokenising the text. 9.2 tokenise the text using unnest_tokens(). We will convert the text of our books into a tidy format using unnest_tokens() function. Learn how to use the tidytext package in r to analyze twitter data. Unnest_tokens expects all columns of input to be atomic vectors (not lists) how do i fix this without using the it would indeed be nice to hv a better documentation. 9.2 tokenise the text using unnest_tokens(). These functions will strip all punctuation and normalize all whitespace to a single space character. I am using r 3.5.3 and have installed and reinstalled dplyr, tidytext, tidyverse, tokenizers, tidyr, but still keep receiving the error. Tidytext will allow us to perform efficient text analysis on our data. We then need to load the package along with the tidyverse to pull out the hashtags from the text of each tweet we first need to convert the text into a one word per row format using the unnest_tokens() function from. Most analysis involves tokenising the text. Error in unnest_tokens_.default(., word, reviewtext) : The tokenizers package offers fast, consistent tokenization in r for tokens such as words, letters arguments used in tokenize_words() can be passed through unnest_tokens() using the the not all tokenization packages are the same. 9.2 tokenise the text using unnest_tokens(). Unnest_tokens(tbl, output, input, token = words, format = c(text, man, latex, html, xml), to_lower = true, drop = true. It worked a few weeks before but now my output is only na. So you may be missing a step. We load a dataframe of stopwords, which is included in the tidytext package. I am using r 3.5.3 and have installed and reinstalled dplyr, tidytext, tidyverse, tokenizers, tidyr, but still keep receiving the error. This package implements tidy data principles to make many text mining tasks easier, more effective, and consistent with tools already in wide use. Required packages & supporting functions tidytext package for reading the file containing the dataset unnest_tokens function. So you may be missing a step. 5.text mining and nlp using text mining package(tm) etc. You can install the rtweet package from cran by executing install.packages(rtweet). R/unnest_tokens.r defines the following functions: Error in unnest_tokens(., word, text, token = regex, pattern = unnest_reg) : You can use the tidytext::unnest_tokens() function in the tidytext package to magically clean up your text! This package implements tidy data principles to make many text mining tasks easier, more effective, and consistent with tools already in wide use. The novel is saved as a plain text. And i might be asking too much, but if all the standard commands in r worked with. Df %>% unnest_tokens(word, text) %>%. So you may be missing a step. You have no option to configure that currently. The tidyr package provides the ability to separate the bigrams into individual words using the separate() function. 2 sentiment analysis with tidy data. I would now like to 'untidy' that data frame back to its original.
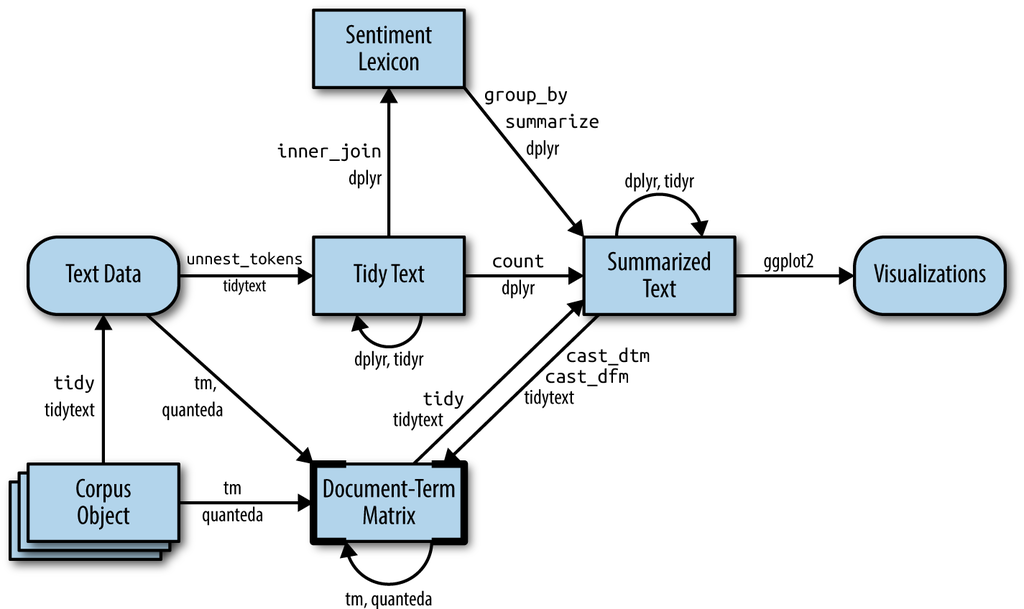
R/unnest_tokensr defines the following functions: unnest_tokens. Casting a data frame to a documenttermmatrix
Unnest_Tokens Package In R: R/unnest_tokens.r defines the following functions:



0 Tanggapan:
Post a Comment